Релиз 17.04.2025
Добавлены функции:
-
Автомасштабирование ML-сервиса на основе метрик. Теперь в режиме хостинга «Автоматический» можно настроить запуск и остановку инстансов сервиса на основе количества запросов, времени ответа, нагрузки на CPU.
Пример настройки
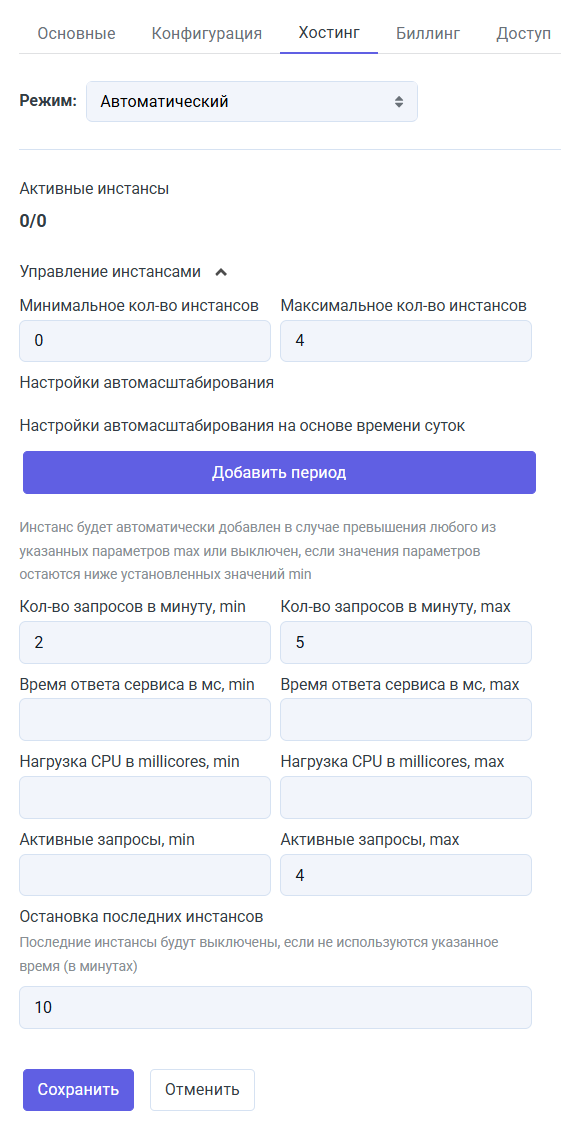
-
Метод для потоковой генерации: predict-with-config-stream. Работает аналогично
predict-with-config-v2-stream, но принимает на вход объект, а не строку, поэтому не требует экранирования символов.Пример запроса
curl -L 'https://caila.io/api/mlpgate/account/just-ai/model/gemini/predict-with-config-stream' \
-H 'MLP-API-KEY: <api_token>' \
-H 'Content-Type: application/json' \
-d '{
"config": {
"temperature": 0.8
},
"data": {
"stream": true,
"model": "gemini-1.5-pro",
"max_tokens": 20000,
"messages": [
{
"role": "user",
"content": "What is the weather like in San Francisco?"
}
]
}
} -
Метод для подсчета количества токенов в запросе: count-tokens. Пока работает только для моделей Claude.
Пример запроса
curl -L 'https://caila.io/api/adapters/openai/count-tokens' \
-H 'Authorization: Bearer <api_token>' \
-H 'Content-Type: application/json' \
-d '{
model": "just-ai/claude/claude-3-5-sonnet-latest",
"messages": [
{
"role":"user",
"content":"What is the weather like in San Francisco?"
}
]
}'