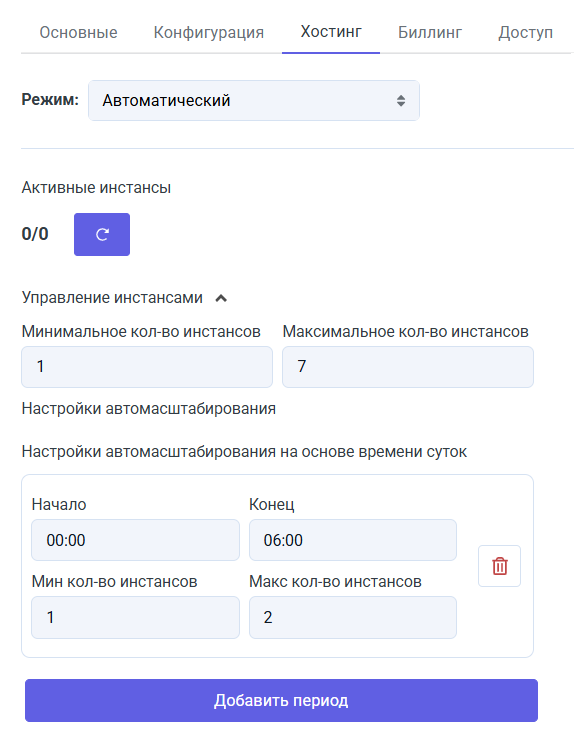
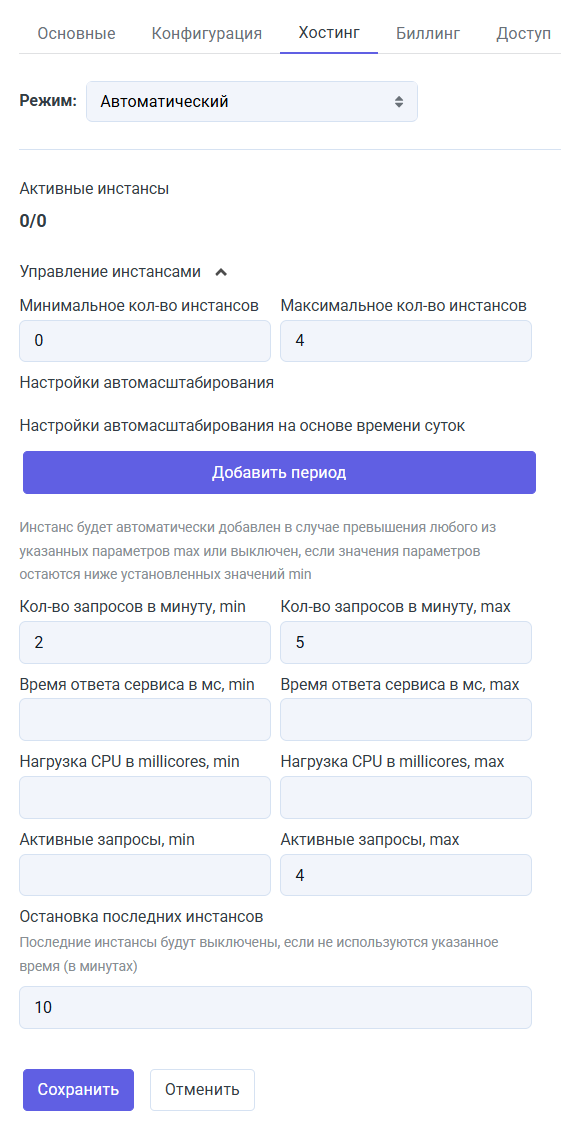
Релиз 10.07.2025
В новый релиз Caila включены доработки для улучшения безопасности и контроля:
- Настройка лимитов для API-ключей: возможность устанавливать ограничения на сумму расходов за период, размер запроса, количество запросов в минуту, ML-сервисы и модели, к которым разрешено делать запросы.
- Email-уведомления о том, что время жизни API-ключа скоро истекает.
- Аудит действий пользователей: Caila протоколирует создание, изменение и удаление основных объектов — ML-сервисов, образов, датасетов, ресурс-групп, серверов и т. д. Отчет доступен администраторам аккаунта в разделе Аккаунты в Conversational Cloud.